Interdependencies and code stability
As engineers, we have the tendency to over-engineer our solutions, make our code as reusable as possible. We make our code DRY (don't repeat yourself). Although these are good rules to go by in most cases, they can also lead to problematic maintenance issues. In our DRY-quest, we can create unstable, yet reusable code that is used in more than one place. Sometimes it is ok to write our code WET (write everything twice). Why? Because it creates more stable code around interdependencies.
The stability rule #
The stability rule is very simple. In this rule, stability means the likeliness the code will change. Every function, module, or UI component we write, is as stable as the lowest stability of its dependencies. Think about it. If a dependency changes, our code has to (potentially) change as well.
Every function, module, or UI component we write, is as stable as the lowest stability of its dependencies
But how do you determine the stability of dependencies? This is, unfortunately, no exact science. It depends heavily on the type of dependency as well. We can set third-party packages to fixed version numbers, making them very stable. We can assume browsers API will, most likely, not change. But the code we write ourselves can and will change.
Most of our time spent during development is around unstable code. We focus on implementing UI and features that are each unique and add a different value to a user or business. This makes the code by default less reusable. But by using systems, architecture, and patterns as underlying decisions, we can stabilise the foundations. Thus increasing the stability of the code written. Some examples are design systems, validation libraries or state management libraries.
Dependency graphs #
A good way to understand the stability of your code, is to look at the dependency graph. This is a visual representation of how various components and functions are connected. Lets look an an example. In this example we are looking at an "activities" page that has a few small things going on. First of all we see that it shows a table with the available data. Next there is also a possible to search. And lastly we can create a new activity.
Everything black is an UI component, purple are actions (e.g. API calls), and green are model-related (e.g. validation/transformation).
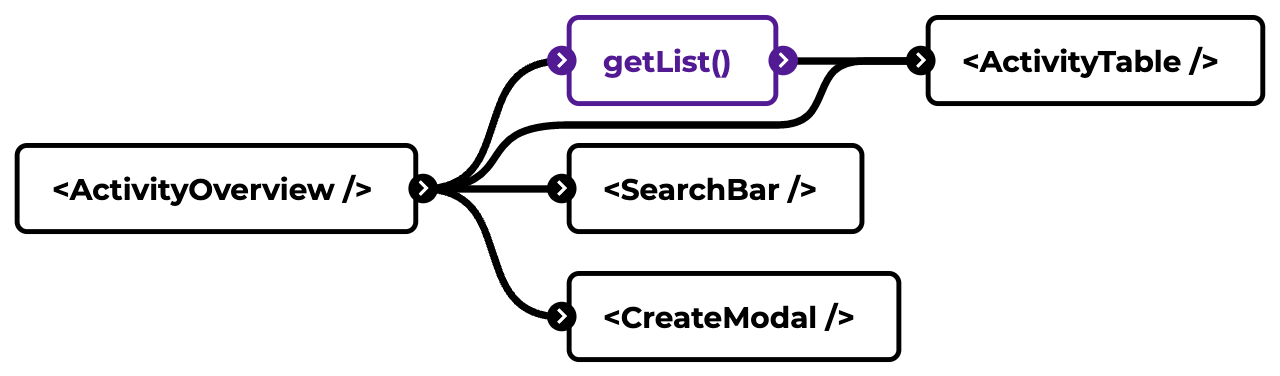
One potential unstable example in this graph is the getList() action. It is highly likely that such an action is used elsewhere. But is the output in the correct format for our table? What if we want it grouped on users in this view, but not in other views? Instead of building different views on the data in the getList() function, we should actually apply code splitting.
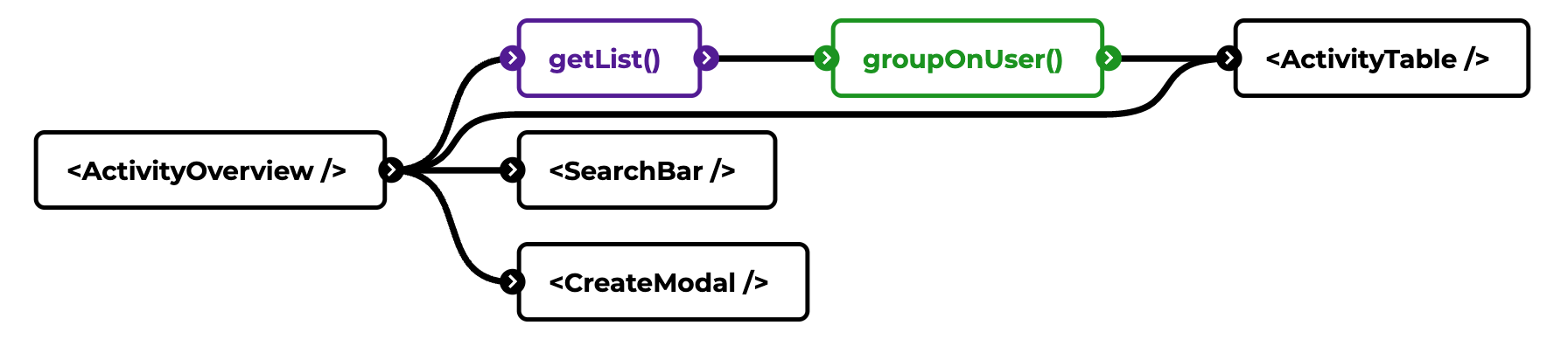
In a similar way we can determine other areas that might get unstable as well. Such as "who is responsible to handle the actual pagination of data?". The answer can depend on many things. Does pagination exists similar everywhere? Does it happen consistently based on "page and page size" or do some use "limit and offset"?
Wrapping up #
By asking these type of questions based on a dependency graph, one can spot areas of improvements. In the end, parts of your code will remain unstable. But, you can create highly stable and independent parts of you code that just work. You will see the quality of your code increase and become more maintainable.